





Trusted by Leading Companies Worldwide
Putting ML models to production at your company is broken
ML is different from traditional software. Handing models off to DevOps only means losing precious time and going to market slower.
Using a fragmented MLOps stack means you're paying hefty fees for each tool or using OSS with little support.
We fix that.

Your ML command center
High-growth teams need an impactful tool to blitzscale profits
Right tool for the right job
Achieve faster, more collaborative experimentation with notebooks
Unleash the full potential of your scripts
Elevate your coding experience and superpower your local IDE with SSH
Seamless data connection
Effortlessly connect your data across cloud buckets
Simple 1-click integration
Powerful UI and API interface
Powerful infrastructure at scale
Supporting batch, serverless, and live API workflows
Autoscaling
Bulk Inference
CPUs & GPUs
UI or APIs
Scheduling
Kubernetes
JobsFlow
Any Cloud
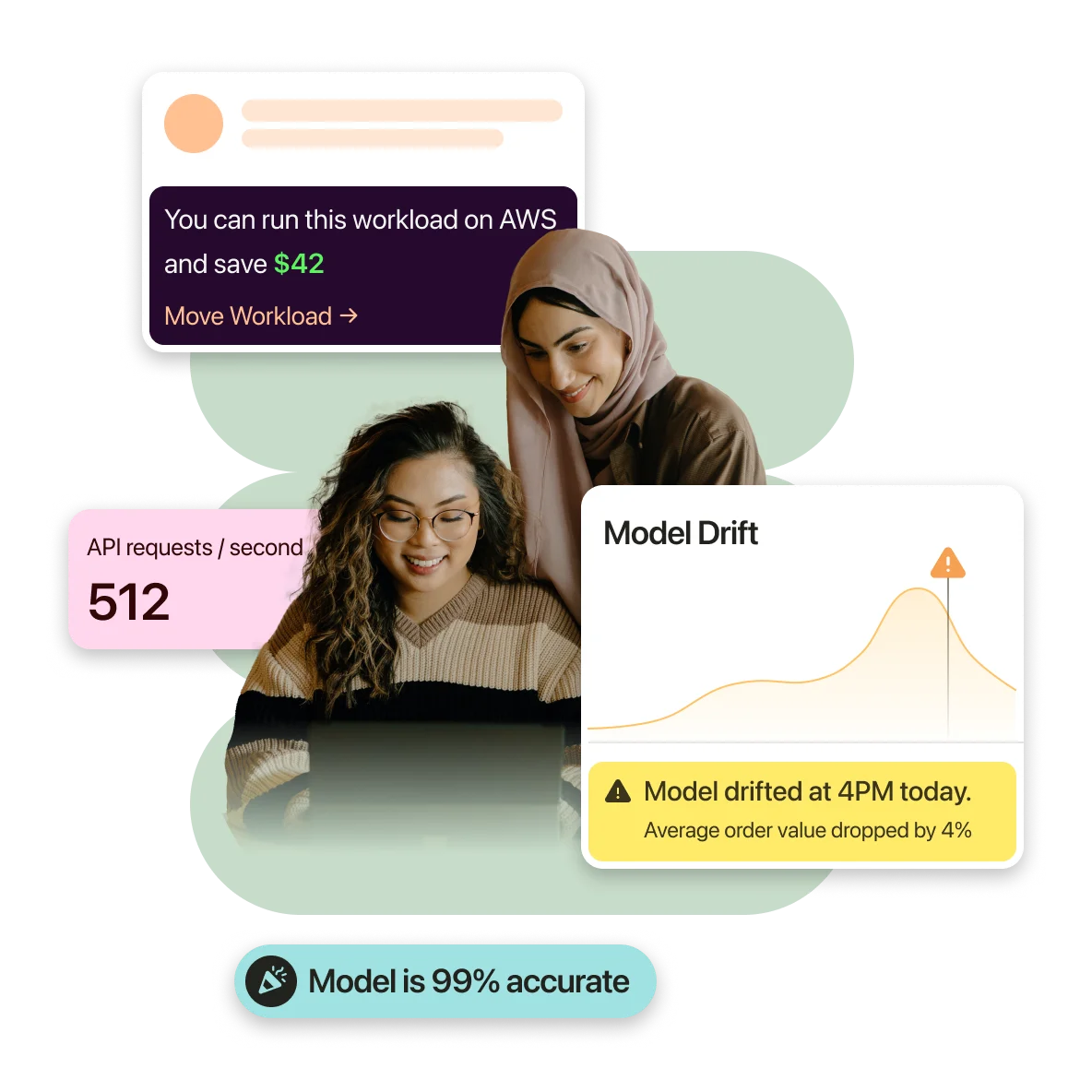
Observe changes, react effectively, stay ahead
Transform your research, drive better outcomes with real-time monitoring, stay on top of the wild. Lifecycle solved.
Experiment Tracking
Live Monitoring
Rules based Workflow
Alerts & Notifications
Project Artifacts
Trends
We manage your entire ML lifecycle. And you?
1. Reduce project costs
Project-level cost budgeting and reports.
Hybrid-cloud workflow distribution.
Underutilized resource management.
Auto-hibernating inactive deployments.


2. Get actionable insights
Ace your team's KPIs.
Automate routine tasks.
Intelligent alerting & actions based on model metrics.
Real Time metrics from experiments to deployments.
3. Go to market faster
White-glove support over Slack.
Boost active learning with unique datasets.
Deploy to production, independent of DevOps.
A/B test models in production for quicker feedback.

We fit like a piece in your puzzle
Setup with existing workflows and tools in less than 60 minutes.



More superpowers to your team
Workspaces
Simple and faster team onboarding, creating the industry-standard for ML teams
Multi Cloud Support
Run across clouds without the learning curve
Kubernetes Support
Simple UI for Kubernetes, and dedicated servers
Roles and Permissions
Maintain checks and balances across your team
Lightning fast GPU support
Run P100s, V100s, A100s and more on your cloud
Self hosted Apps
Host any application and share with a click
Reports and Activity
Track and monitor your project costs & resource usage
Docker Support
Bring over your Docker images
SSH
Securely tunnel into your active machines
Oh, and we're pretty secure!
SOC2 Type 2 compliant
Regular vulnerability assessments and penetration testing
HIPAA in progress
Data & Model Access logs